Bevezetés a
GPGPU
programozásba
Készítette: Závodszky Gábor / @Zega21
Hidrodinamikai Rendszerek Tanszék
Kurzus követelmények:
- A kurzuson való részvétel
- minden alkalom előadás és laborgyakorlat
- félévközi project megvalósítása
- 10 perces beszámoló az utolsó órán
Szükséges alapismeretek:
Alapvető linux felhasználói ismeretek:
- SSH csatlakozás (putty)
- File műveletek
- Fordítás gcc -vel
(A kurzus folyamán elsajátítható)
Szükséges alapismeretek:
Alapvető C/C++ programozási ismeretek:
- a fordító működése (kapcsolók)
- header fileok
- parancssori argumentumok kezelése
- pointerek működése
- több dimenziós tömbök
- file műveletek
(A kurzus folyamán NEM elsajátítható (bár gyakorolható). A következő órára ezekre az ismeretekre mindenkinek szüksége lesz! TUTORIAL a honlapon!)
Felhasznalható irodalom
- CUDA by Example - J. Sanders, E. Kandrot, Addison-Wesley, 2011
- CUDA Application Design - Rob Farber, Elsevier, 2011
- The CUDA Handbook - Nicolas Wilt, Pearson, 2013
- Programming massively parallel processors - David B. Kirk, Wen-mei W. Hwu, Elsevier, 2010
- Hivatalos CUDA dokumentáció
Tipp a fóliákhoz
- A fóliák letölthetőek, ha a query string tartalmazza a "print-pdf" szöveget
- (?print-pdf az url végére).
GPU-k rövid története
(Graphics Processing Unit)
- Mi az a GPU?
- Mi a GPGPU?
- Honnan jön?
Kezdetek
 |
 |
A videokártya a polygon számításokat gyorsítja
 |
|
Programozható pipeline kialakulása
Ahol most tart a real-time grafika
 |
A GPU-ról röviden
- A GPU-k teljesítménye számokban
- Hol használják?
- Mitől gyors
Elméleti számítási teljesítmény
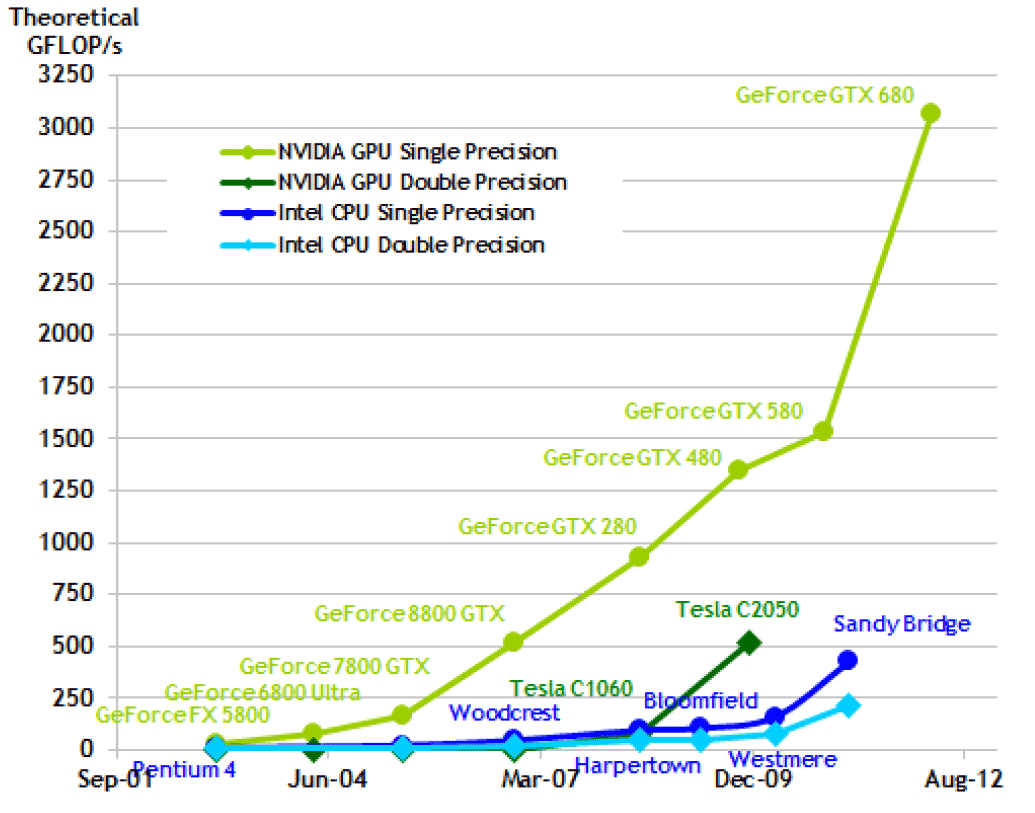
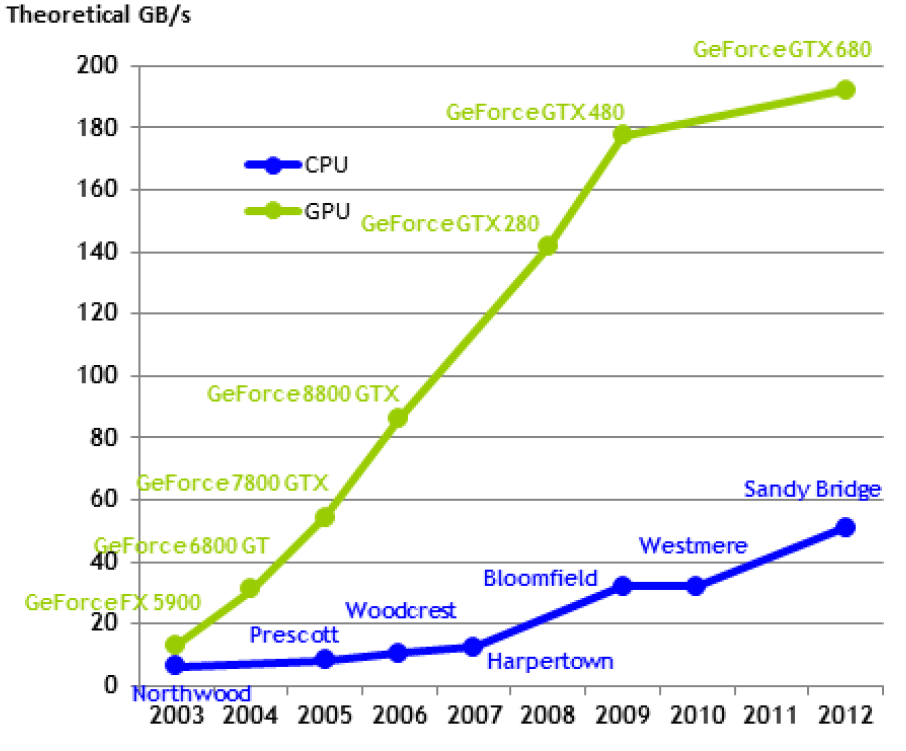
Elméleti memória sávszélesség
Felhasználási területek
 |
|
|
 |
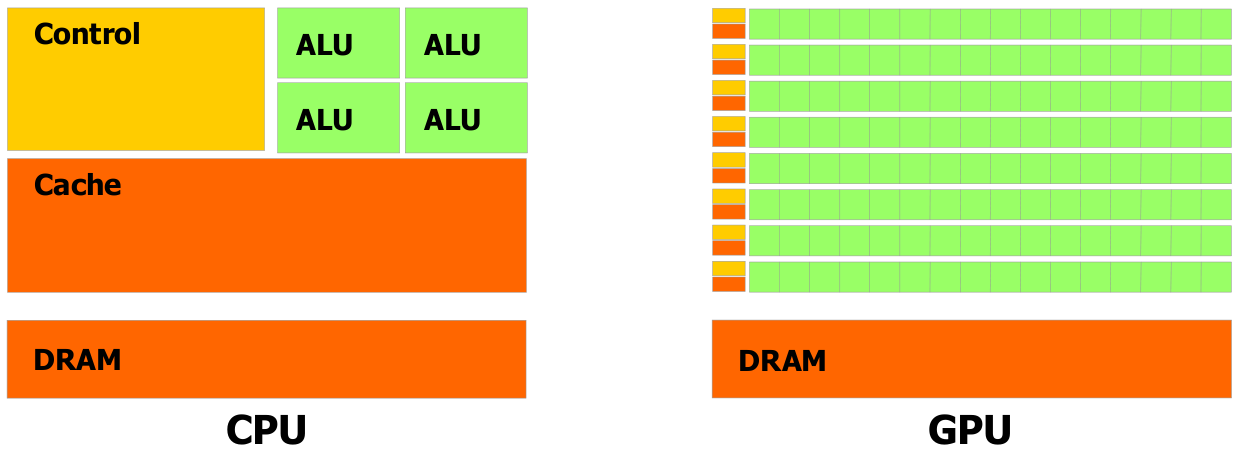
CPU vs. GPU felépítés
A CUDA C/C++ nyelv
- Preprocesszor a C/C++ nyelvhez
- Host: Teljes C++, Device: subset
- Runtime API, a driver API-ra épít
Alapfogalmak
- Heterogén számítás - egy időben futó számítás CPU-n és GPU-n
- "könnyű" szálak - CPU: max. 24, GPU - 2860 / MP = 30+k
- RAM - VRAM
Erős skálázás - Amdahl törvénye
Ha egy fix méretű probléma skálázódásáról beszélünk újabb processzorok hozzáadásával.
\[ S(N) = \alpha + (1 - \alpha)N \]
- Ahol S a maximális elérhető gyorsulás, alfa a párhuzamosítandó program soros futásidőhányada, N a párhuzamos végrehajtóegységek száma
Amdahl törvénye
Suppose a car is traveling between two cities 60 miles apart, and has already spent one hour traveling half the distance at 30 mph. No matter how fast you drive the last half, it is impossible to achieve 90 mph average before reaching the second city. Since it has already taken you 1 hour and you only have a distance of 60 miles total; going infinitely fast you would only achieve 60 mph.
Gyenge skálázás - Gustafson törvénye
Ha a probléma mérete
\[ S(N) = \frac{N}{1 + (N-1)\alpha } \]
- Ahol S a maximális elérhető gyorsulás, alfa a párhuzamosítandó program soros futásidőhányada, N a processzorok száma
Gustafson törvénye
Suppose a car has already been traveling for some time at less than 90mph. Given enough time and distance to travel, the car's average speed can always eventually reach 90mph, no matter how long or how slowly it has already traveled. For example, if the car spent one hour at 30 mph, it could achieve this by driving at 120 mph for two additional hours, or at 150 mph for an hour, and so on.
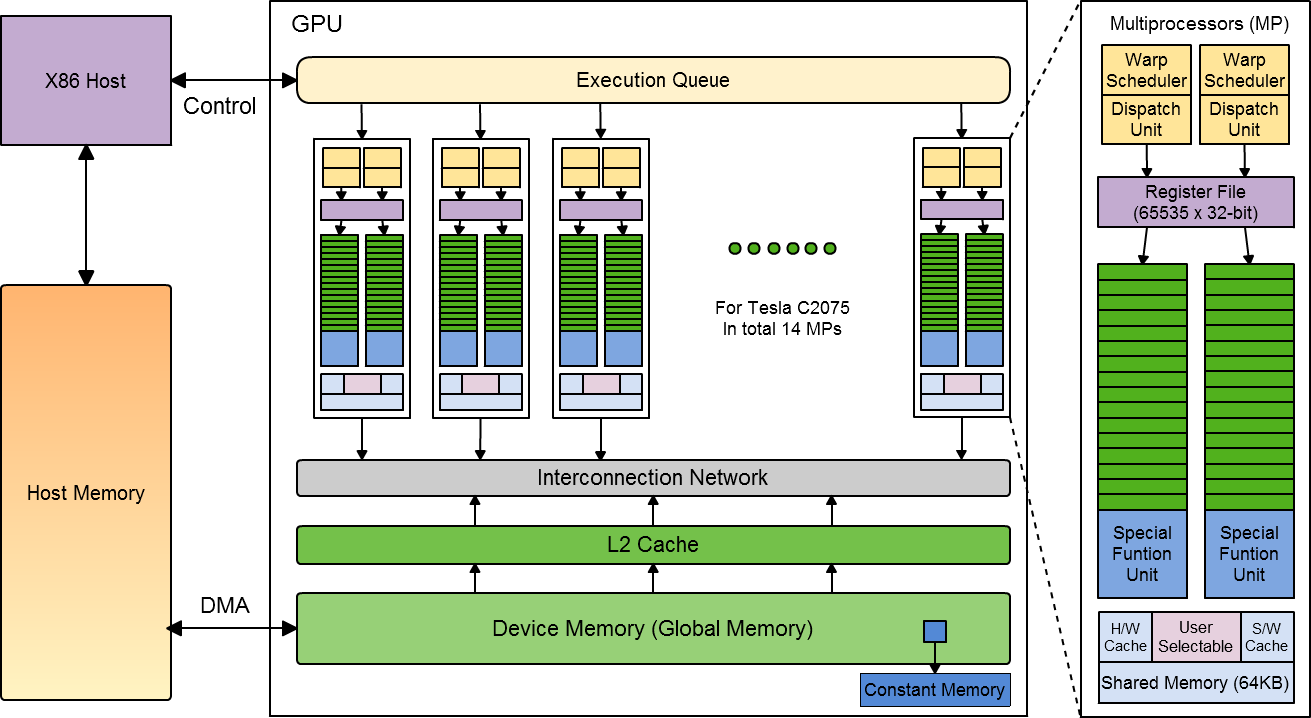
A GPU-k szerkezete
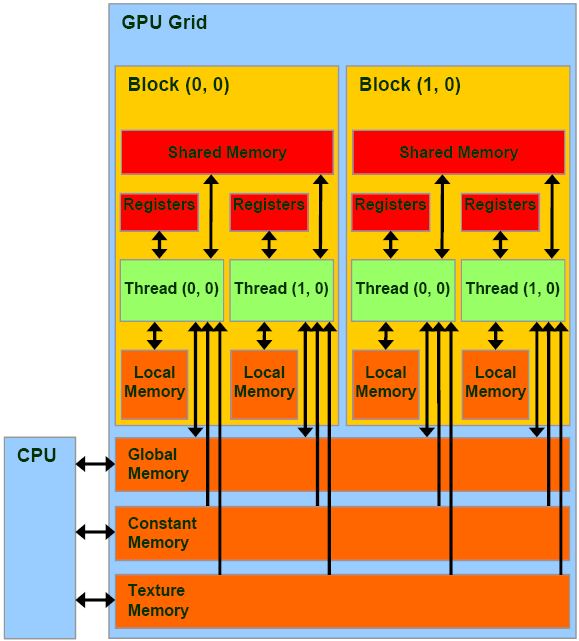
A GPU-k memória felépítése
CUDA Hello Wolrd
#include <stdio.h>
#include <cuda.h>
__global__ void square_array(float *a, int N)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx<N) a[idx] = a[idx] * a[idx];
}
int main(void)
{
float *a_h, *a_d;
const int N = 10;
size_t size = N * sizeof(float);
a_h = (float *)malloc(size);
cudaMalloc((void **) &a_d, size);
for (int i=0; i<N; i++) a_h[i] = (float)i;
cudaMemcpy(a_d, a_h, size, cudaMemcpyHostToDevice);
int block_size = 4;
int n_blocks = N/block_size + (N%block_size == 0 ? 0:1);
square_array <<<a n_blocks, block_size >>> (a_d, N);
cudaMemcpy(a_h, a_d, sizeof(float)*N, cudaMemcpyDeviceToHost);
for (int i=0; i<N; i++) printf("%d %f\n", i, a_h[i]);
free(a_h); cudaFree(a_d);
}
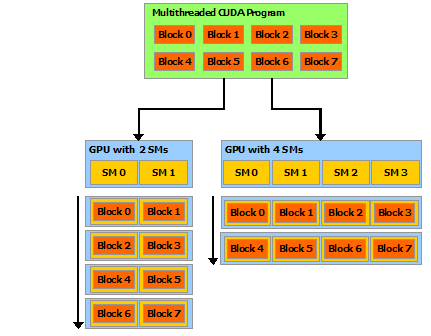
A CUDA skálázódása
A GPU programozás 3 alapszabálya
- Pakold az adatokat a GPU-ra, és tartsd ott!
- Lásd el a GPU-t elég feladattal!
- Fókuszálj az adatok újrafelhasználására!
Pakold az adatokat a GPU-ra, és tartsd ott!
A GPU PCIe sínnel csatlakozik a géphez.
| Sávszélesség (GB/s) | A PCIe-hez képest | |
| PCIe x16 2.0 | 8 | 1 |
| GPU globális memória | 200 | 25 |
Lásd el a GPU-t elég feladattal!
A GPU-k teljesítménye teraflop nagyságrendű. Ha egy kernelindítás 4 µsec, és egy 1 teraflopos kártya 4 órajelciklus alatt végez el egy floating point műveletet, a kernelnek nagyjából 1 millió műveletet kell végeznie, hogy elfedje az indítási "költséget". Ha csak 2 µsec-ig dolgozik egy kernel, a GPU az idő 50%-ban csak áll.
Fókuszálj az adatok újrafelhasználására!!
Egy single float32 tárolása 4byte, ennyit kell olvasni, majd visszaírni. Egy teraflopos kártyának 8terabyte/s sávszélességet kellene biztosítani, hogy maximális kihasználtsággal fusson. Ez körülbelül 40x meghaladja a globális memória sávszélességét, és körülbelül 400x a rendszermemóriáét.
CUDA demonstráció
GDC 2009 videó YouTube-on.
2011 folyadék dinamika YouTube-on.
Választható projectek
- Saját ötlet (+ - +++)
- Particle advection in velocity field (++)
- Game of Life szimuláció (+)
- Mass-Spring-Damper 2D/3D (+/++)
- Ising model 2D/3D (+/++)
- N-test szimuláció 2D/3D (+/++)
- Marching cubes GPU (++)
- Fractal generator (+)
- 2D Lattice Boltzmann CFD (++)
- Delunay háromszögesítés (++)
- 3D primitives collision check library (++)
- GPU Hash library (++)
- Fejlesztés létező 3D LBM kódon (+++)
- Quantum gravitációs kód átültetése GPU-ra (+++)